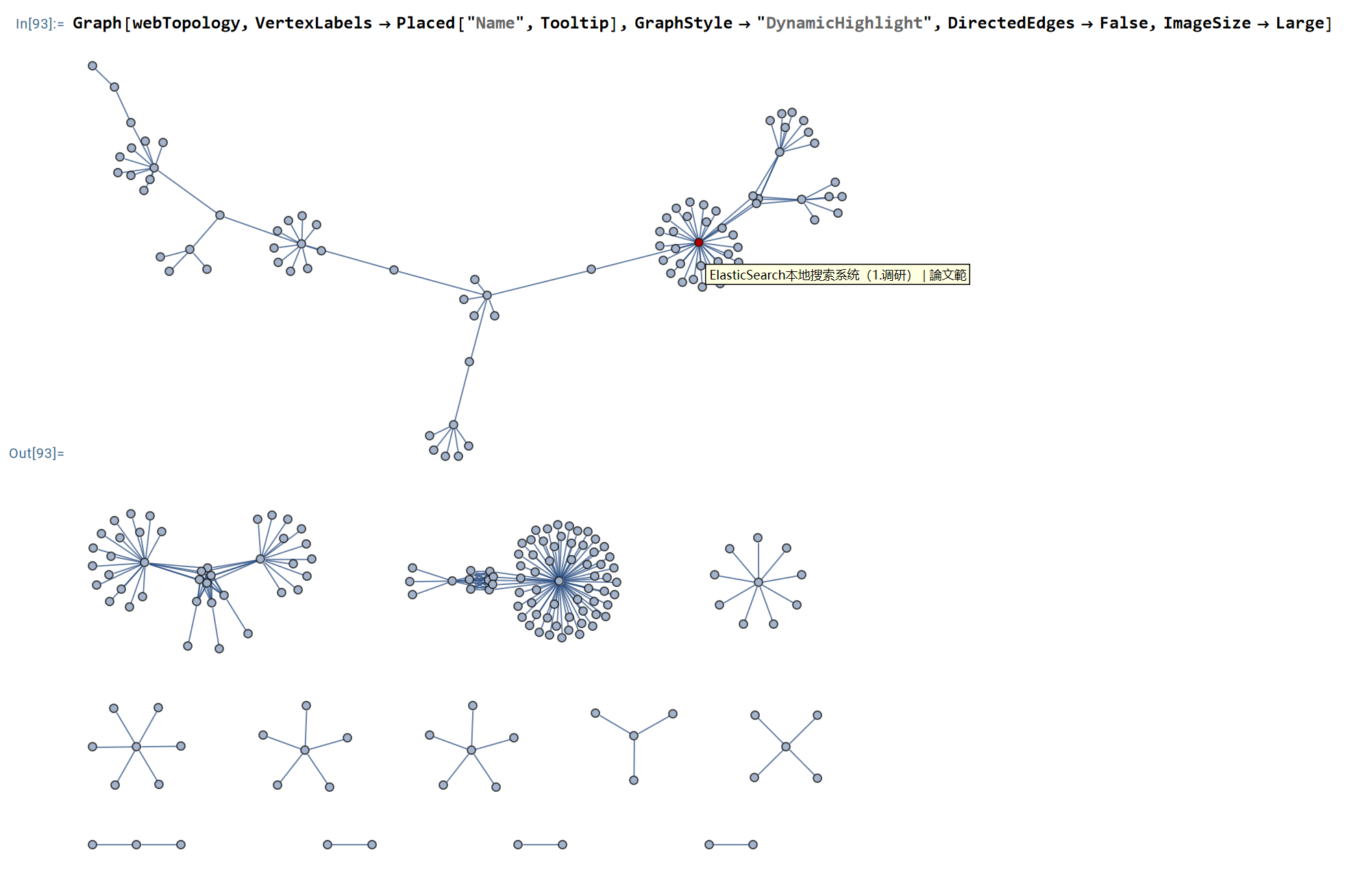
爬取静态博客网页以分析本网站拓扑结构
1. 系列文章网页爬虫第一课:从案例解构爬虫基本概念填坑18年:我总结的CSS选择器爬虫数据持久化方式的选择爬取静态博客网页以分析本网站拓扑结构python程序的性能测试及瓶颈分析Python工程项目的规范开发指南 2. 需求分析 提取各个网页的超链接, 用于对网站拓扑结构进行分析; 提取各个网页的其它元数据, 用于对博客文章从多个角度进行统计; 不要提取全文数据, 因为我此次不做文本的语义分析. 3. 功能设计 获取博客所有文章的列表. 通过文章列表对每篇文章进行索引, 获取元数据. 对于单个博客站点的爬取数据,在磁盘上用JSON进行存储. 可视化: 网站的拓扑结构(本文目标), 获取每篇文章的元数据(用于将来的文本分析), 包括: title 本文URL(且中文没有转义编码) 发表时间 分类 tags 外部超链接(external URL) 正文文本(暂时不提取正文, 怕麻烦; 而且目前用不着文本分析) 4. 技术实现4.1. 配置基础工具1234567891011121314151617181920import requestsfrom bs4 import BeautifulSoupimport reimport pprintfrom urllib import...

爬虫数据持久化方式的选择
系列文章网页爬虫第一课:从案例解构爬虫基本概念填坑18年:我总结的CSS选择器爬虫数据持久化方式的选择爬取静态博客网页以分析本网站拓扑结构python程序的性能测试及瓶颈分析Python工程项目的规范开发指南 存储方案的选择爬虫数据的存储目前有以下几种方式: TXT文本文件存储 JSON文件存储 CSV文件存储 MySQL存储 MongoDB文档存储 Redis缓存存储 Elasticsearch搜索引擎存储 RabbitMQ的使用 作为个人使用, 从数据的”存储便捷性-多种工具间的兼容性-可拓展性”的角度出发, 我选择综合使用下述方案: 在本地, 当数据文件较少时, 用”JSON文件存储”; 在本地, 当数据文件较多时, 用”MongoDB文档存储”; 在云端, 用”Elasticsearch搜索引擎存储”, 同时本地的MongoDB数据的文件定期上传到云端的Elasticsearch. 上面的过程慢慢来. 在本文中今天先学会JSON文件存储. JSON文件存储python的json字符串形如: 123456json_str = [ { "name": "hellokitty", ...
大模型在自动驾驶领域的应用(下:可行性).tbd
1. 系列文章大模型在自动驾驶领域的应用(上:可能性)语言大模型的本地部署.lite自有数据辅助的大语言模型问答精度改进大模型在自动驾驶领域的应用(下:可行性).tbd 背景本文承接大模型在自动驾驶领域的应用(上:可能性)结尾的问题: 大模型在智慧交通/自动驾驶领域的落地的前景会是怎样的? 可行性如何?

我神不知鬼不觉地成了GitHub开源贡献者
前因后果最近在写博客文章ChatGPT 广泛应用带来的风险和危机的时候, 需要较多的引用参考文献. 于是我想着找找, 看看hexo有没有插件用于作为参考文献的. 一番机缘之下, 我找到了hexo-reference-new, 遗憾的是, 这个插件只能支持引文的”硬编码”( 即[^1.]这样的格式), 不支持[^someReference.], 自然也无法支持文献的自动编号(auto numbering). 引文无法自动编号简直是反人类好吧~ 😞 巧合的是, 瞌睡来了送枕头. 我在这个repo中看到了这样一个PR: modified render logics to support non-number footnote marks. 这个PR实现功能正是用[^someReference.]编制引文, 并对引文自动编号. 遗憾的是, hexo-reference-new的管理员对这个2019年并没有兴趣合并. 更遗憾的是, modified render logics to support non-number footnote marks作者的repo也有部分代码是落后于hexo-reference-new的, 难道鱼与熊掌就不可兼得了嘛? 我擦~...
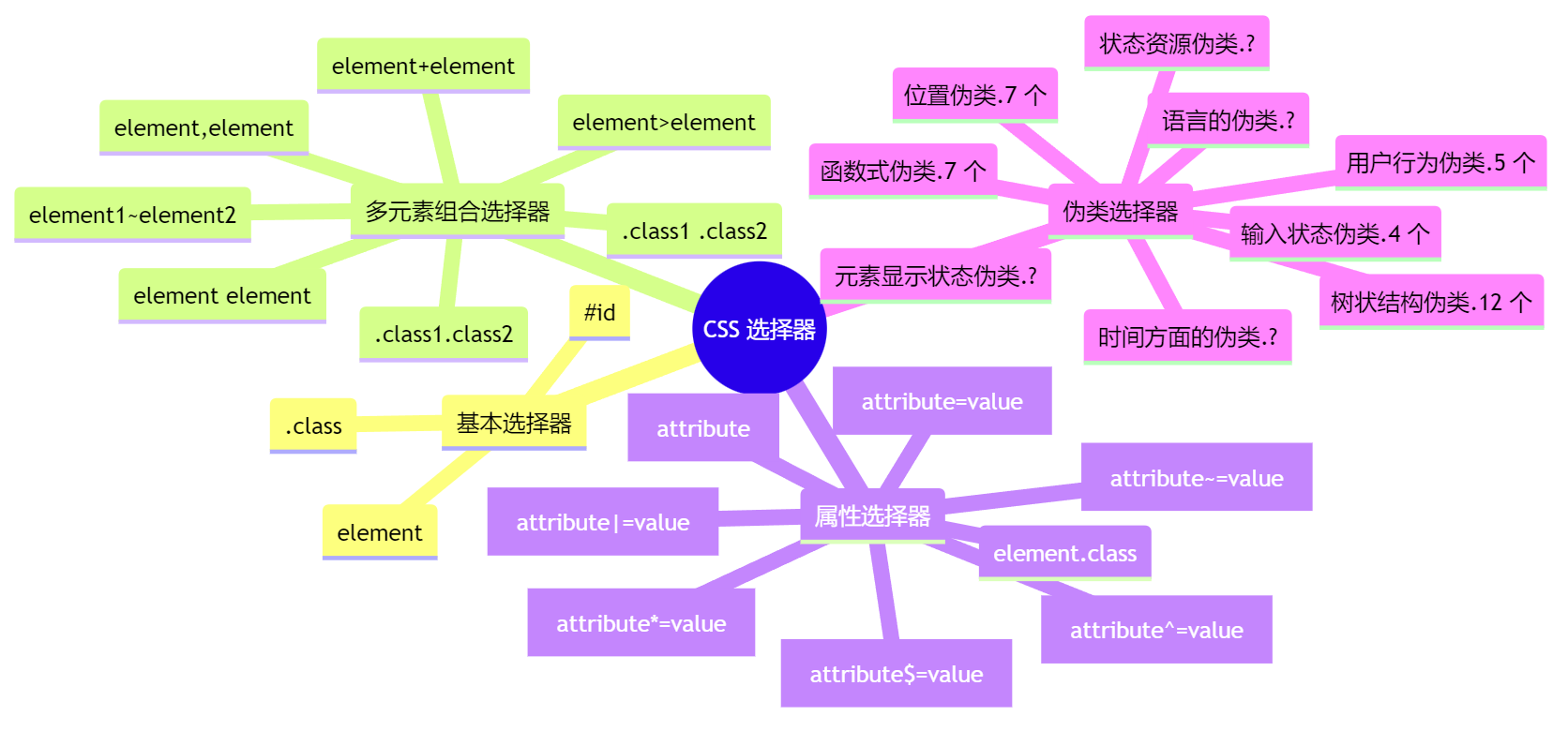
填坑18年:我总结的CSS选择器
系列文章网页爬虫第一课:从案例解构爬虫基本概念填坑18年:我总结的CSS选择器爬虫数据持久化方式的选择爬取静态博客网页以分析本网站拓扑结构python程序的性能测试及瓶颈分析Python工程项目的规范开发指南 CSS选择器这个坑我18年前就该填了. 十八年前, 我还是一个沉不住气的小朋友, 遇到困难随时准备放弃的那种. “CSS选择器”就是其中一个. 这么多年来, 这个坑时不时地折磨我一下, 让我错失很多机会. 痛定思痛, 今天我就要在两篇材料的辅佐下, 把它彻底解决掉. 下面首先给出全文总结出的CSS选择器的概览. 真是简单啊~ mindmap root((CSS选择器)) 基本选择器 element .class #id * 多元素组合选择器 element,element element element element>element element+element element1~element2 .class1.class2 .class1 .class2 属性选择器 ...
网页爬虫第一课:从案例解构爬虫基本概念
系列文章网页爬虫第一课:从案例解构爬虫基本概念填坑18年:我总结的CSS选择器爬虫数据持久化方式的选择爬取静态博客网页以分析本网站拓扑结构python程序的性能测试及瓶颈分析Python工程项目的规范开发指南 缘起kindle中国在2024-06-30彻底关闭之后, 用户购买的电子书甚至都不能下载了. 太可恶了! 西方发达资本主义国家的老板们, 良心真是大大滴坏~ 资本家们算是指望不上了, 咱们还是积极自救吧… 瞅着将近一千本的电子书, 真是欲哭无泪啊 😒😭 还好有大神从天而降, 发明了神器: Kindle_download_helper. 将这个开源程序作为第一个研究对象. 对于这个工具的试用方法可以参见这篇教程: 一键批量下载 Kindle 全部电子书工具 + 移除 DRM 解密插件 + 格式转换教程 (开源免费). 对了, 万一要是没有大神怎么办? 一千本电子书如果手动下载, 一本书1分钟, 1000分钟就是17个小时, 我擦~ 一天花17个小时搞这破事儿, 太不划算了. 不行, 我也要学会爬虫. 虽然说 “爬虫玩的好, 牢饭吃到饱”, 但是咱可以偷偷摸摸地玩嘛~ 🤣 说干就干, 这篇就借着Kindle_download_helper的东风,...

自有数据辅助的大语言模型问答精度改进
系列文章大模型在自动驾驶领域的应用(上:可能性)语言大模型的本地部署.lite自有数据辅助的大语言模型问答精度改进大模型在自动驾驶领域的应用(下:可行性).tbd 工具选择这篇文章最初是在一年前我构思的,目的在于通过引用外部数据源,改善LLM回答的精确性,减少“幻觉”。但自己一直没有推动 一年后的今天,我觉得该自用的RAG系统做个了解,才惊觉这个技术已经有了长足的发展:Dify、AnythingLLM、Langflow等已经超脱了LangChain [1] 、LlamaIndex 等基础设施的范畴 [2] ,可以直接为终端用户提供开箱可用的方案。 君子性非异也,善假于物也。作为非专业研究者,我是时候放下执念,从善如流了。通过比较,我最终选择了 RAGFlow . 相比于其它解决方案,RAGFlow对我的吸引力主要来自于如下: 🍔 兼容各类异构数据源 支持件类型丰富文,包括 Word 文档、PPT、excel 表格、txt 文件、图片、PDF、影印件、复印件、结构化数据、网页等。 🛀 全程无忧、自动化的 RAG 工作流 全面优化的 RAG 工作流可以支持从个人应用乃至超大型企业的各类生态系统。 大语言模型 LLM...

填坑:(neo)vim中自动切换中文输入法
系列文章neo|vim高效编辑的基本配置进化neovim到lin.nvim风味我的Learn Lua in Y minutes(lin.)nvim启用Copilot补全lin.nvim中安装其它插件ubuntu工作环境初始化脚本一款流畅的、用于重构代码的neovim插件:ChatGPT.nvim填坑:(neo)vim中自动切换中文输入法lin.nvim中配置编程语言LSP补全 工作动机用(neo)vim编辑中文有个特别蛋疼的地方:(neo)vim的模式切换只支持英语,那么在用中文进行文档编辑时,我们往往要先从中文输入法切换为英语输入法;更让人抓狂的是,我们在心流状态下编辑时往往忘了——结果手忙脚乱地把输入法切换一通,这让原本沉浸式写作状态非常别扭。 今天终于忍无可忍了,于是找到了下面的解决方案。 解决方案 如何让 Neovim 中文输入时自动切换输入法 –> im-select.nvim. 选择该方案是因为该插件是用lua语言编写的。 终于把“vim中文编辑时的输入法自动切换”这个坑给填平了。

一款流畅的、用于重构代码的neovim插件:ChatGPT.nvim
系列文章neo|vim高效编辑的基本配置进化neovim到lin.nvim风味我的Learn Lua in Y minutes(lin.)nvim启用Copilot补全lin.nvim中安装其它插件ubuntu工作环境初始化脚本一款流畅的、用于重构代码的neovim插件:ChatGPT.nvim填坑:(neo)vim中自动切换中文输入法lin.nvim中配置编程语言LSP补全 ChatGPT试用体验Copilot 就不多说了,它是微软的代码生成工具,擅长的是“无中生有”——属于建构。 而今天无意中发现了一款 neovim 插件ChatGPT.nvim。同 Copilot 不同的是,ChatGPT.nvim 更侧重于重构:可以重构代码,也可以重构自然语言书写的文本。 下面是 Youtube 是该插件用于重构代码的演示视频: % youtuber video dWe01EV0q3Q %% endyoutuber % 从视频中可见,ChatGPT.nvim 充分利用 vim 编辑器的无键盘操作理念,整个过程非常流畅,个人认为比 Obsidian 中的 AIGC 工具更加……能让人保持心流状态。😎 备忘一下,日后再说。 nvim备选AI插件按照“从高到低”的硬核程度排序: ⚡...

通过Nginx实现不同前缀的三级域名指向不同网站服务器
实际难题最近我有一个新的需求:通过同一台云服务器提供在线PPT浏览服务。我不想将这个online slide的文件直接上传到原来的博客网站的文件根目录:因为online slide和blog分别是由不同的团队负责,每次blog内容上传都会把online slide的文件清空。那么,将online slide和blog的文件夹在磁盘上进行物理隔离就是一个自然而然的解决办法——此时它俩的根文件夹将作为不同server的root。真实烦恼~ 此时,我的问题就变成了:如何通过配置Nginx,实现不同前缀的三级域名指向不同网站服务器? 解决方案依次完成如下三个步骤: 在阿里云的域名解析中,为一级域名papers.fun申请二级域名slide.papers.fun. 参考《🔥二级域名的创建、配置和解析,买一个域名,有无限个域名可以使用的方案》 为二级域名slide.papers.fun申请SSL(免费版是单域名证书). 参考《数字证书管理服务(原SSL证书)》 在Nginx的配置文件nginx.conf为二级域名slide.papers.fun配置SSL证书....
