
基于机器视觉的桌面窗体组件的目标检测.notFinished
系列文章微信公众号数据采样试验mitmproxy实时数据处理appium对手机微信的自动化测试winAppDriver对桌面微信的自动化测试场景文字识别的快速调研UI Automation对桌面微信的自动化测试基于机器视觉的桌面窗体组件的目标检测.notFinished 需求和目标通过自动化测试技术激活软件的流量、进而对软件内容进行爬取, 其中的一个关键点就是如何定位到软件的窗口组件, 从而进行后续的操作。 在本系列文章前面的文章中, 我们通过inspect.exe等软件, 预先将桌面软件窗体组件”硬编码”到了代码中. 但是这种方式的弊端在于: 不仅增加了程序员的工作量, 而且当目标组件的属性变化时, 原先的自动化测试爬虫就失效了. 总之, “硬编码船体组件”是非常僵化的方式. 我们需要一种更加鲁棒的方式, 实现对窗体目标组件的识别, 而目标检测(object detection)技术, 就是一种对目标进行智能化检测的手段. 在本文, 我将基于YOLO架构, 实现一个目标检测模型, 用于识别软件窗体组件. 本文的主要内容包括: YOLO目标检测的基本概念和原理 YOLOv5目标检测的关键技术 对电脑屏幕中的软件窗体组件进行目标检测 方案与实施

UI Automation对桌面微信的自动化测试
系列文章微信公众号数据采样试验mitmproxy实时数据处理appium对手机微信的自动化测试winAppDriver对桌面微信的自动化测试场景文字识别的快速调研UI Automation对桌面微信的自动化测试基于机器视觉的桌面窗体组件的目标检测.notFinished 方案设计在尝试了手机端Appium、PC端WinAppDriver(基于Appium)的自动化测试失败之后, 我们在本文尝试了基于微软的UI Automation的PC端微信自动化测试的方案. Microsoft UI Automation(UIA)是适用于Microsoft Windows的辅助功能框架. 它满足了辅助技术产品和自动化测试框架的需求, 通过提供对用户界面(UI)信息的编程访问来实现. 此外, UI Automation还使控件和应用程序开发人员能够使其产品具有辅助功能. 对于UIA的简要介绍可以参考此文 [1] ; 而明确此文中UIA的几个概念, 则是使用该框架的一个必要前提. 在本节我将用大白话将这几个概念做个备注. 它们是: UI Automation tree(UI自动化树) 日常生活中, 当我们打开Windows系统、它也正常运行时, 系统中所有基于窗体的软件,...

winAppDriver对桌面微信的自动化测试
系列文章微信公众号数据采样试验mitmproxy实时数据处理appium对手机微信的自动化测试winAppDriver对桌面微信的自动化测试场景文字识别的快速调研UI Automation对桌面微信的自动化测试基于机器视觉的桌面窗体组件的目标检测.notFinished 需求和目标在winAppDriver 对桌面微信的自动化测试中, 我们实现了通过抓取网络流量, 对公众号内容的收集. 为了更高效地对内容进行批量采集, 我们需要一种自动化的方法, 从而批量地激活网页流量. 因此, 在appium 对手机微信的自动化测试中, 我们试图用Appium对手机微信进行自动化操作, 同时以PC作为中间代理, 从而在PC上截获手机流量, 对内容进行爬取. 但这种方法存在两个缺陷: 需要对手机的Android进行root, 并植入用户证书. 而从Android12之后, 系统不再信任用户证书. 为了绕后系统安全措施, 我们需要进一步对手机微信app进行逆向; 通过手机微信进行爬取, 需要长时间无法使用手机. 如果任务量太大, 可能需要专门的手机. 成本太高. 所以需要反思: 我们是否问对了问题? 是否有其它的方式. 回到此项任务的需求, 我们只是需要点击微信公众号中的链接, 从而触发流量....

开源情报技术及资源框架
...

appium对手机微信的自动化测试
系列文章微信公众号数据采样试验mitmproxy实时数据处理appium对手机微信的自动化测试winAppDriver对桌面微信的自动化测试场景文字识别的快速调研UI Automation对桌面微信的自动化测试基于机器视觉的桌面窗体组件的目标检测.notFinished 需求与目标在该系列的前述文章中, 我们已经实现了对微信订阅号的文章的爬取. 所使用的方法就是利用mitmproxy截获流量, 并直接从网络流量中重构、还原文章内容及其其它元数据. 但是, 在这个过程中我需要在手机微信的app中, 手动地浏览并打开订阅号中的文章. 非常低效与耗费人工. 因此, 我需要一个工具, 帮我自动浏览微信订阅号(从而激活网络流量, 顺利抓取文章内容). 这就需要使用到手机端的软件自动化测试技术. 目前在手机端进行自动化测试的工具, 其中功能比较完善的是Appium [1] . 本文的目标就是: 利用Appium对手机软件的自动化测试方法, 对手机微信app自动地翻页、点击相关文章, 从而激活流量. (其余的抓取流量并重构公众号文章内容的功能, 我在前面的系列文章已经完成) 方案与实施端口转发:手机到WSL2如果是在Windows系统中,...
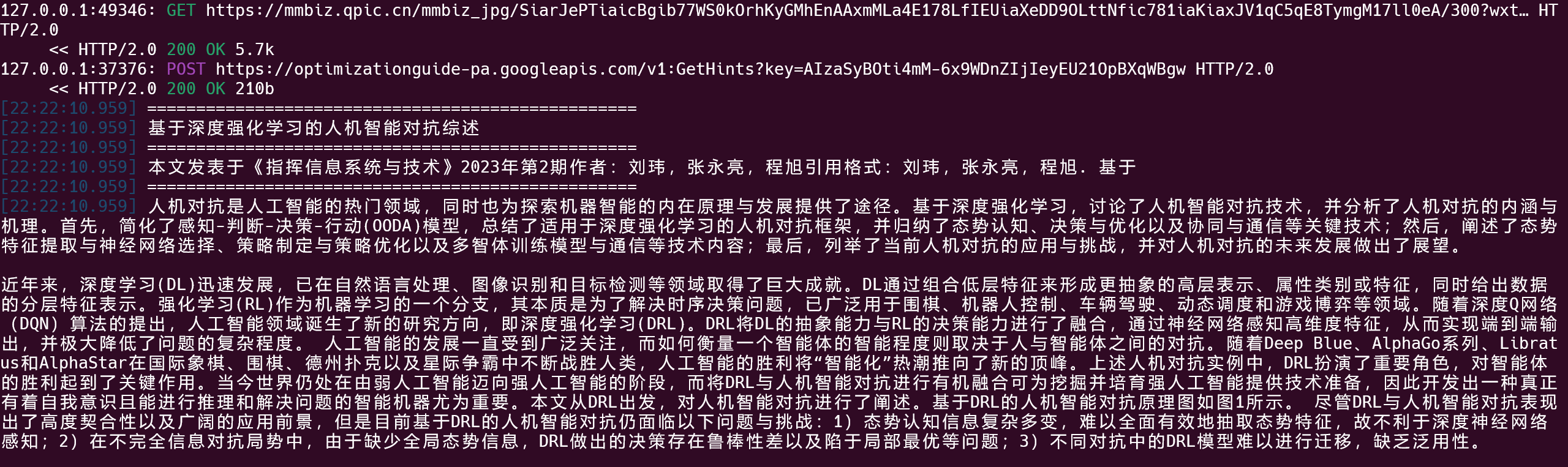
mitmproxy实时数据处理
系列文章微信公众号数据采样试验mitmproxy实时数据处理appium对手机微信的自动化测试winAppDriver对桌面微信的自动化测试场景文字识别的快速调研UI Automation对桌面微信的自动化测试基于机器视觉的桌面窗体组件的目标检测.notFinished mitmproxy安装配置我使用的是window 11系统的wsl环境. 这个蛋疼的环境在使用mitimproxy抓包时有个蛋疼的地方: 我们需要在wsl中安装Linux版本的命令行 [1] ; 但是我们还需要按照window的方式安装SSL证书 [2] . 当然如果不放心, 可以把window版本的mitimproxy安装、配置一遍; 同时在wsl中按照Linux的方式把mitimproxy也安装、配置一遍. mitmproxy抓包实验Step 1: 将Windows的系统代理设置为127.0.0.1:8080 Step 2: 在wsl终端启动mitmproxy 1./mitmproxy 随便打开一个公众号, 点开某篇文章, 可以看到mitmproxy的终端中抓包时的工作状态如下所示: 上述界面中, mitmproxy抓取内容对应的网页部分如下图所示: 上述两图说明,...
微信公众号数据采样试验
系列文章微信公众号数据采样试验mitmproxy实时数据处理appium对手机微信的自动化测试winAppDriver对桌面微信的自动化测试场景文字识别的快速调研UI Automation对桌面微信的自动化测试基于机器视觉的桌面窗体组件的目标检测.notFinished 技术路线我们采用抓包的方式, 通过截获网络传输数据, 实现对微信公众号内容的爬取. 而启动该过程的前提条件就是激活PC端的微信客户端, 这需要借助于自动化测试工具. 自动化测试工具根据测试对象种类的不同, UI自动化测试测试工具大致可以分为三类 [1] : App端: Appium、Airtest、AutoJS. Web端: Selenium、Puppeteer、Cypress. PC端: WinAppDriver、Pywinauto[2]. 在选择自动化测试工具时, 我更看重软件的易用性、普适性、兼容性. 在上述的”三端”中: Appium-Selenium-WinAppDriver或多或少都以Appium作为基础平台; 而且使用者比较多, 其可靠性经过了广泛地验证, 目前都还在活跃地开发中. 因此, 在”三段”中,...
Python工程项目的规范开发指南
系列文章网页爬虫第一课:从案例解构爬虫基本概念填坑18年:我总结的CSS选择器爬虫数据持久化方式的选择爬取静态博客网页以分析本网站拓扑结构python程序的性能测试及瓶颈分析Python工程项目的规范开发指南 学习动机以史为鉴, 可以少走弯路, 这对于一个新手来说是难得的经验. 在文章 Python开发避免踩坑指南 中, 作者提到: 写这篇文章的主要目的是帮助刚刚入门Python的同学和从其他语言转过来的同学,快速熟悉Python一般的生态圈,比如IDE使用、虚拟环境、项目结构管理、Debug、版本管理等等. 本文主要包含以下几个方面: 配置开发环境 虚拟环境管理和pip 项目目录结构 代码风格 版本管理 这些经验对于python程序开发的规范性是非常经典的指南. 而随着新技术、新工具的发展, 这些python程序开发规范有了新的演绎. 为了简明起见, 我将上述开发规范精简为以下几个方面、并按照循序渐进的顺序排列: 配置开发环境 程序版本管理 项目目录结构 代码风格 配置开发环境在文章 [1] 中, 作者使用virtualenv作为开发环境隔离的工具. 在我看来,...

计算技术的稻香村(新手涨见识)
...

python程序的性能测试及瓶颈分析
系列文章网页爬虫第一课:从案例解构爬虫基本概念填坑18年:我总结的CSS选择器爬虫数据持久化方式的选择爬取静态博客网页以分析本网站拓扑结构python程序的性能测试及瓶颈分析Python工程项目的规范开发指南 正文