mitmproxy实时数据处理
系列文章
- 微信公众号数据采样试验
- mitmproxy实时数据处理
- appium对手机微信的自动化测试
- winAppDriver对桌面微信的自动化测试
- 场景文字识别的快速调研
- UI Automation对桌面微信的自动化测试
- 基于机器视觉的桌面窗体组件的目标检测.notFinished
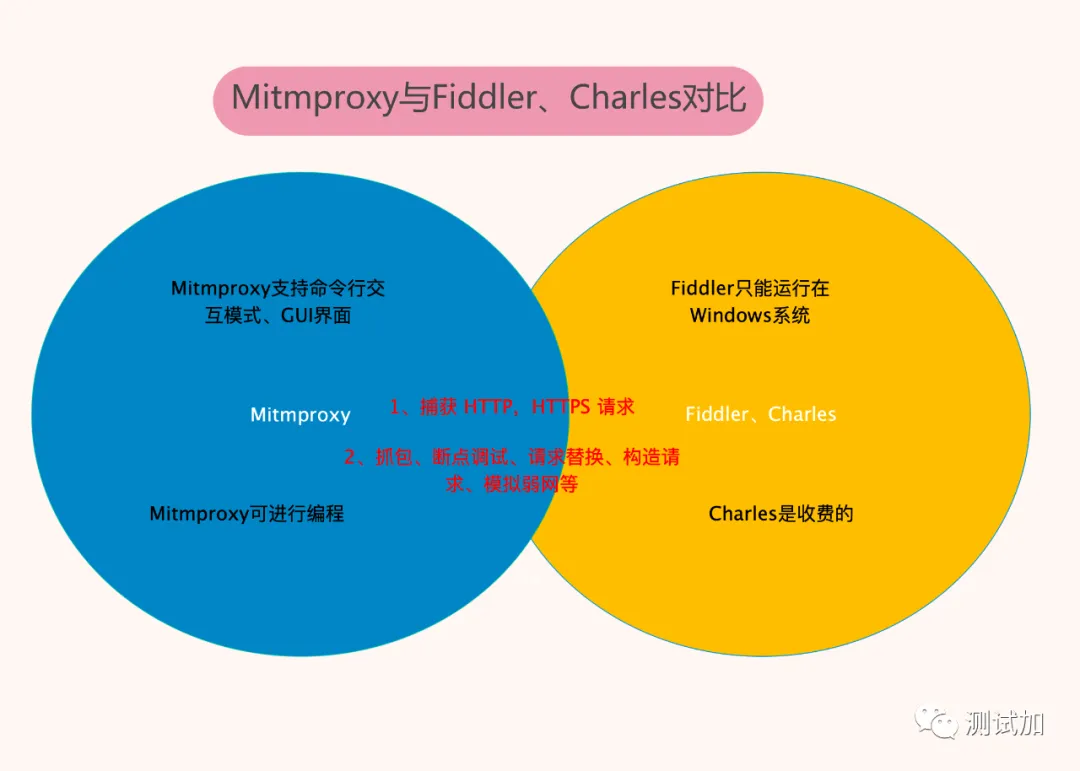
mitmproxy安装配置
我使用的是window 11系统的wsl环境. 这个蛋疼的环境在使用mitimproxy抓包时有个蛋疼的地方:
当然如果不放心, 可以把window版本的mitimproxy安装、配置一遍; 同时在wsl中按照Linux的方式把mitimproxy也安装、配置一遍.
mitmproxy抓包实验
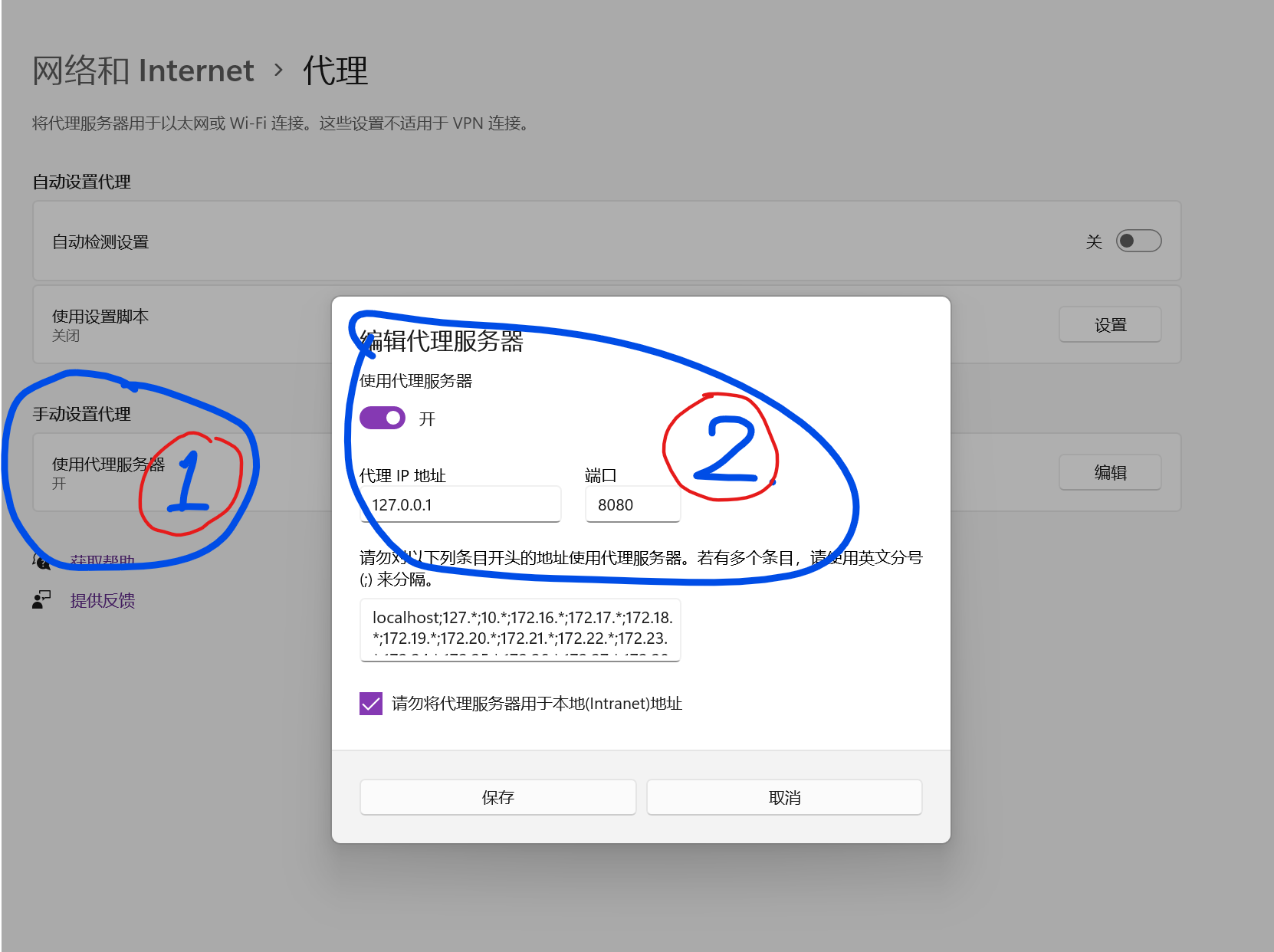
Step 1: 将Windows的系统代理设置为127.0.0.1:8080
Step 2: 在wsl终端启动mitmproxy
1 | ./mitmproxy |
随便打开一个公众号, 点开某篇文章, 可以看到mitmproxy的终端中抓包时的工作状态如下所示:
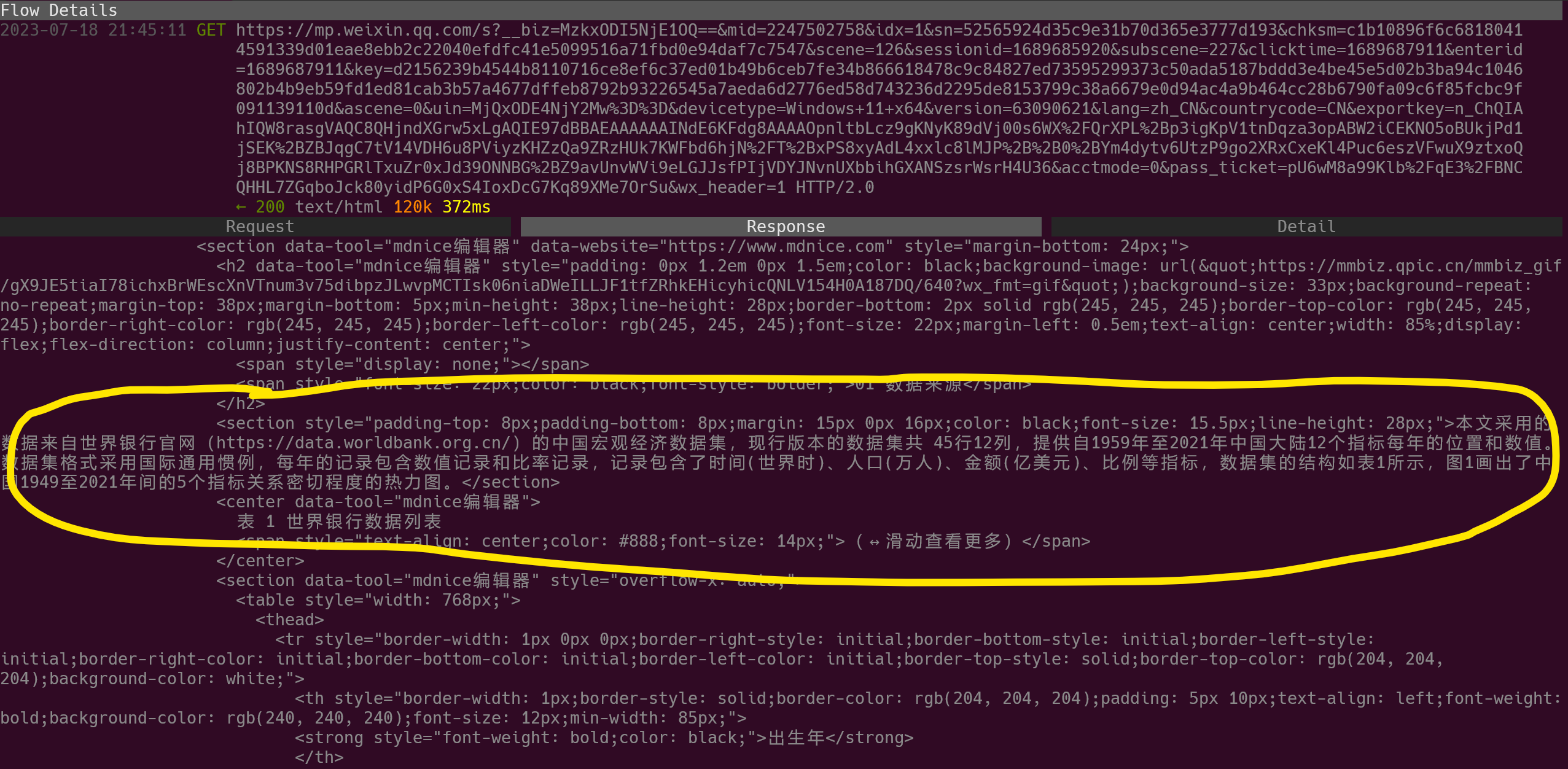
上述界面中, mitmproxy抓取内容对应的网页部分如下图所示:
上述两图说明, 已经成功通过mitmproxy抓取到公众号的文章内容.
实时数据的编程处理
- 目标
- 本文只是验证python编程对mitmproxy数据进行实时处理的可行性. 出于简化实验的目的, 我们本文只实现一个简单的功能:
将提取到的文章内容, 用logging打印出来.
- 重点
- 一个完整的 HTTP flow 会依次触发requestheaders、request、responseheaders和response。
因此我们在为mitmproxy编写Python脚本时, 目前只需重点关注这四类事件.
- 方法
- 为mitmproxy编写脚本有两种方式:
- [面向过程的编程方式] 针对mitmproxy提供的事件接口, 针对不同的(网络)事件, 定义函数.
- [面向对象的编程方式] 以mitmproxy提供的事件接口作为成员函数, 定义类; 并将该类的对象, 作为addons数组的元素(其中addons是官方提供的插件接口).vim ]
中的文字所示, 它们之间的差别在于编程理念的不同. 本文处于学习目的, 会先用[面向过程的编程方式]完成代码; 然后对该代码加壳, 包装成官方推荐的[面向对象的编程方式]`.
- 方法1
- 定义若干函数, 这些函数实现了某些 mitmproxy 提供的事件.
即, 编写一个 py 文件供 mitmproxy 加载; 该文件中定义了若干函数,这些函数对特定的 mitmproxy 内置事件 [5] 进行处理(我们可以称之为事件处理函数) , 即, mitmproxy 会在某个事件发生时调用对应的函数.
在此, 我们直接给出代码:
1 | import mitmproxy.http |
代码讲解:
我们先用”(mitmiproxy)事件处理函数”的思路, 对流量中微信文章的html进行抓取, 并用日志打印出来. 而流量中的微信文章对应的事件是response, 所以, 我们需要针对HTTP Events中的def response(self, flow: mitmproxy.http.HTTPFlow):事件处理函数编写业务代码即可.
- 方法2
- 定义一个类, 类里面的方法实现了某些 mitmproxy 内置的事件.
类中的方法实际上就是方法1中的事件处理函数.
1 | import mitmproxy.http |
代码讲解: 使用类定义的插件, 好处在于可以将插件的配置参数放在类的__init__方法中, 从而使得插件的配置参数更加灵活. 但是在功能函数response的定义, 几乎完全没啥区别. 所以如果需要对抓包行为等进行更为丰富的定义, 可以多使用”类定义的插件”.
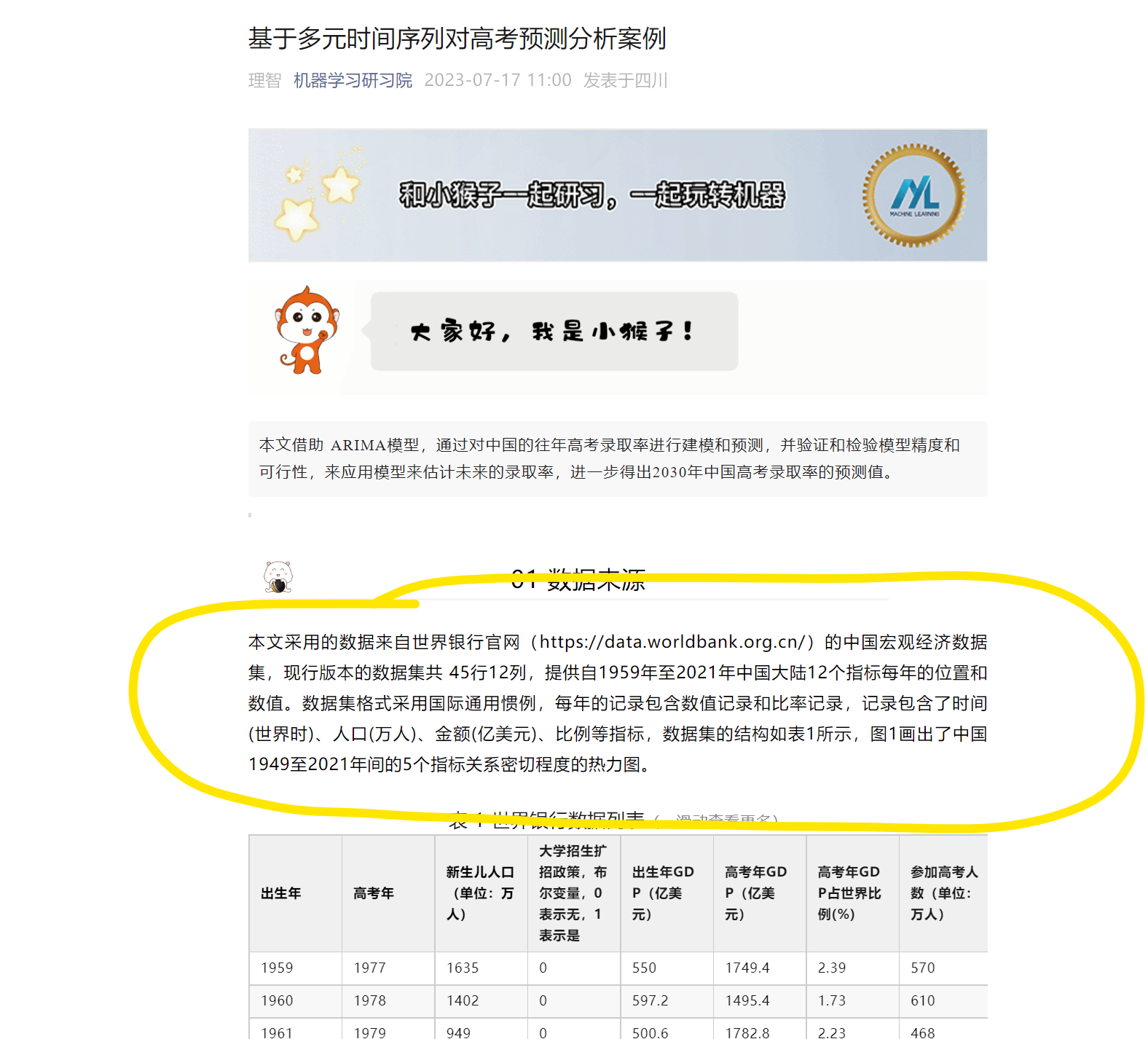
从某网页的流量中抓取文章内容如下图所示:
上述命令行终端日志内容对应的原始网页如下图:
小结与展望
这个hobby project 利用mitmproxy截获网络流量、并从中提取出网页源代码, 进一步解析出网页内容. 这种思路比较硬核, 从底层流量直接抓取所需信息, 理论上可以爬取我们能看到的绝大多部分网页. 因此相比其它网页爬虫, 本文的方法能绕过很多反爬虫的措施, 故具有更广泛的适用性.
然而从本文体现出的技术成熟度来说, 它更像个玩具. 首先, 作为一个完整的爬虫工具, 它还应该具有完善的用户API, 这样才能利于产品的传播. 其次, 代码组织比较随意, 这就导致后续的工程可维护性不好. 最后, 从功能本身来说, 爬虫还应该具有数据持久化的功能.
所以下一步我们要从以下几个方面改善:
将爬取的数据结果, 存入到本机的MonggoDB文档数据库. (参见爬虫数据持久化方式的选择).
按照本博客的Python 工程项目的规范开发指南, 对程序代码的文件目录进行重新组织.
将本项目打包成用户程序, 并以命令行的形式运行.
参考与注释
- 1.mitimproxy的Linux命令行 ↩
- 2.mitmproxy的Windows证书安装方法 ↩
- 3.No module named ↩
- 4.Installation from the Python Package Index (PyPI) ↩
- 5.mitmiproxy内置的事件. 注意, 链接中的文章已经过时. 目前mitmproxy的内置事件包括10大类(而不是链接中提到的6类). mitmproxy内置的10类事件参考官方文档: Event Hooks. ↩