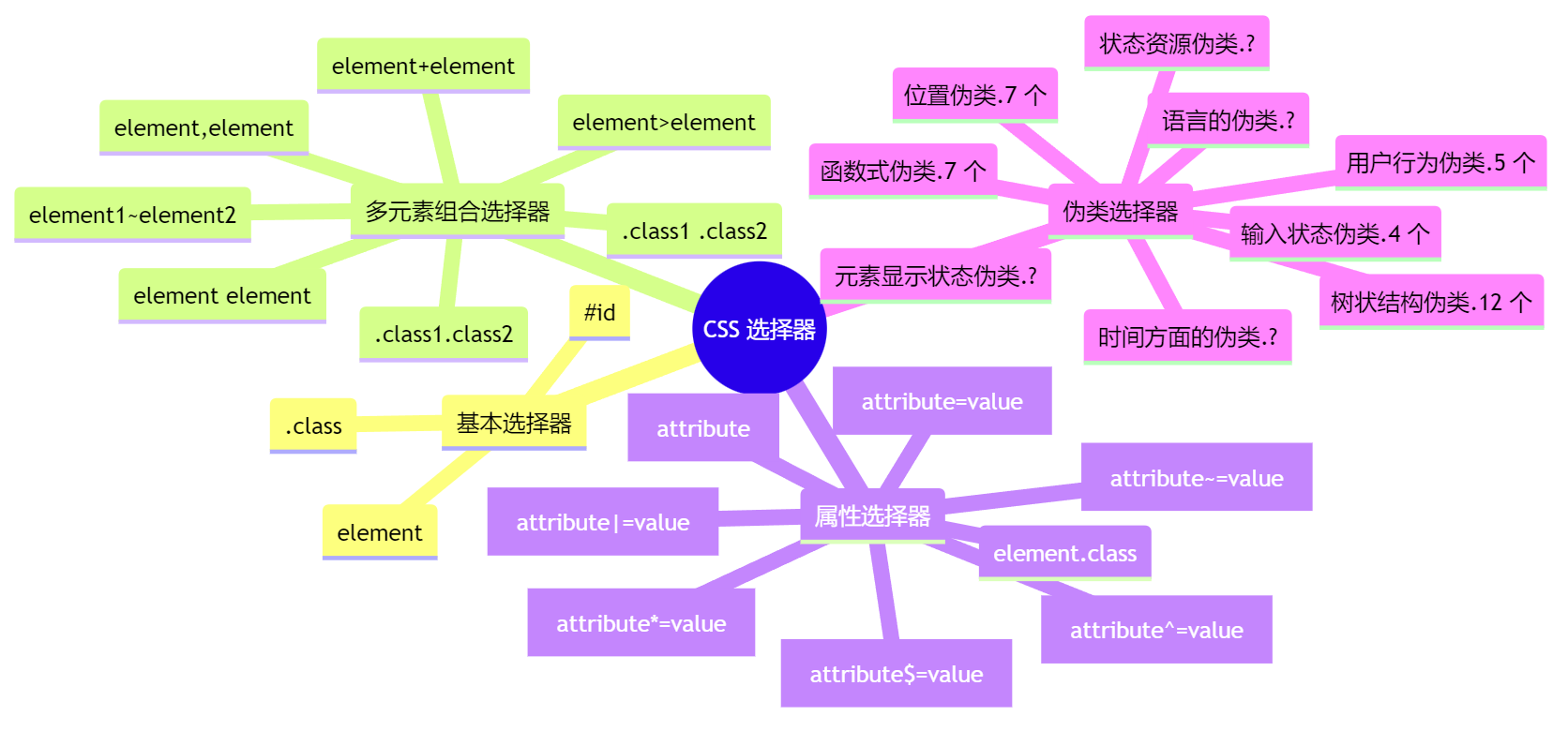
1. 系列文章 网页爬虫第一课:从案例解构爬虫基本概念 填坑18年:我总结的CSS选择器 爬虫数据持久化方式的选择 爬取静态博客网页以分析本网站拓扑结构 python程序的性能测试及瓶颈分析 Python工程项目的规范开发指南 2. 需求分析
提取各个网页的超链接 , 用于对网站拓扑结构进行分析;
提取各个网页的其它元数据 , 用于对博客文章从多个角度进行统计;
不要提取全文数据, 因为我此次不做文本的语义分析.
3. 功能设计
获取博客所有文章的列表.
通过文章列表对每篇文章进行索引, 获取元数据.
对于单个博客站点的爬取数据,在磁盘上用JSON进行存储.
可视化: 网站的拓扑结构(本文目标),
获取每篇文章的元数据(用于将来的文本分析 ), 包括:
title
本文URL(且中文没有转义编码)
发表时间
分类
tags
外部超链接(external URL)
正文文本(暂时不提取正文, 怕麻烦; 而且目前用不着文本分析)
4. 技术实现 4.1. 配置基础工具 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 import requestsfrom bs4 import BeautifulSoupimport reimport pprintfrom urllib import parseimport jsonpp = pprint.PrettyPrinter(indent=4 ) def get_html (url ): try : r = requests.get(url, timeout=30 ) r.raise_for_status() r.encoding = "utf-8" return r.text except requests.HTTPError: return "ERROR"
4.2. 获取所有文章列表 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 def get_articles_list (url ): html = get_html(url) soup = BeautifulSoup(html, "lxml" ) articles_list = [] total_number_title = soup.find("div" , class_="article-sort-title" ).string total_number = re.findall(r"\d+" , total_number_title)[0 ] total_number = int (total_number) articles = soup.select("div.article-sort-item-info" ) for article in articles: publish_time = article.time.string sub_url = article.a["href" ] sub_url = parse.unquote(sub_url) title = article.a.string articles_list.append( {"title" : title, "publish_time" : publish_time, "sub_url" : sub_url} ) return articles_list
4.3. 解析每个网页的元数据 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 def extract_article_detail (url ): html = get_html(url) soup = BeautifulSoup(html, "lxml" ) title = soup.find("title" ).string full_url = parse.unquote(url) publish_time = soup.find("time" , class_="post-meta-date-created" ).string categories = [ cat.string for cat in soup.find_all("a" , class_="post-meta-categories" ) ] tags = [tag.string for tag in soup.find_all("a" , class_="post-meta__tags" )] all_links = soup.find("article" , class_="post-content" ).find_all("a" ) all_links = [link["href" ] for link in all_links] valid_links = [link for link in all_links if re.match (r"^http" , link)] external_links = [] try : for link in valid_links: external_links.append(parse.unquote(link)) except Exception: pass return { "title" : title, "url" : full_url, "publish_time" : publish_time, "categories" : categories, "tags" : tags, "external_links" : external_links, }
最后爬取的博客网页的元数据, 截取部分如下图所示:
上图是由本地的Mathematica代码生成, 文件名为 爬取webscrape静态博客以分析网站拓扑结构.nb .
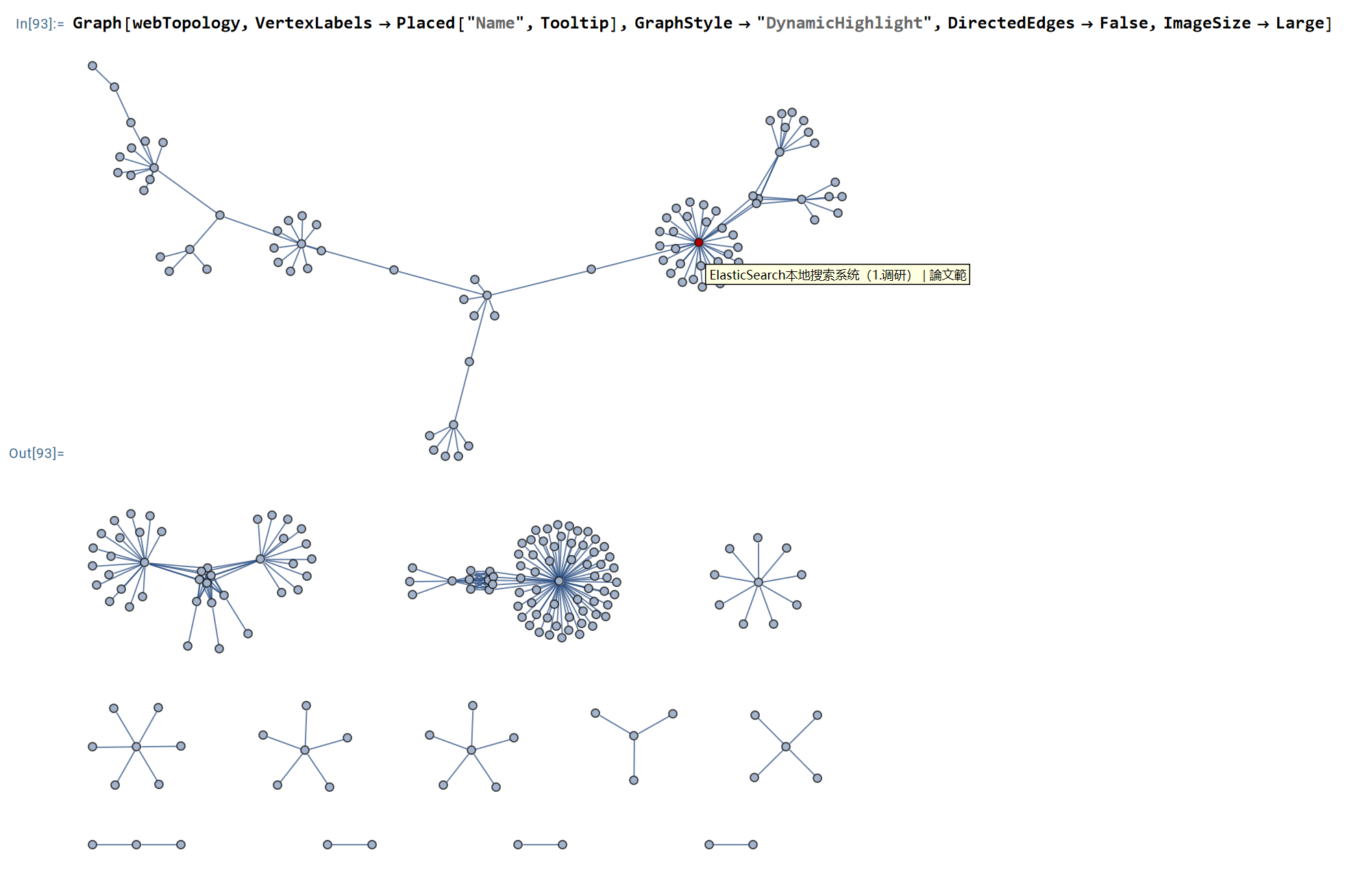
5. 成果展示 最后得到的本博客站点的网页链接的拓扑结构如下图(截至2023年7月14日):
以上仅仅是我们部分利用了爬虫抽取本站元数据, 用以分析本网站的拓扑结构. 从上图可以看出, 网页链接聚类成若干孤岛. 这说明本站的有些内容之间是解耦的, 没有形成紧密的关联. 这也是情理之中, 毕竟, 在规划之初, “机器人学、机器学习、智慧交通”之间就是互不重叠的关系; “技术产品、产业动态、专家观点” 之间也是不重合的. 网页链接形成的若干孤岛说明内容撰写有一定的聚焦.
从本站点采集到的数据不仅可以检查网站拓扑, 利用每篇文章的分类和标签还可以对内容题材的分布进行定性、定量的分析, 这有助于对后续的内容撰写提供方向指引. 文章题材的分布及其可视化 在后续会展开, 目前先用tags 和分类 将就着用.
6. 附录 爬取微信公众号 1 爬取微信公众号 2
近些年来, 很多内容运营商在微信公众号上更新得比自己的网站还积极 — 微信公众号才是亲儿子啊. 而且微信公众号有很多文章非常不错, 是一个重要的信息源.
我们怎么能放过微信公众号这个金矿呢?
但又一想, 南山必胜客 的名头可是不好惹的, 还是放弃吧…
怎么可能放弃? 来都来了, 还是干一篇小的. 咱们是做科研的, 搞科研就得敢于无所不为. 子曰:”怕个毛线啊” 😒
经过调研, 开源程序中有两个repo比较具有技术路线的代表性:
wechat-spider
是利用手机微信APP访问时, 用电脑端的抓包软件截获数据, 并从中解析出微信公众号文章. 这种方式比较硬核.
WeChat_Article
这个是利用了微信个人公众号平台, 通过网页爬虫的形式对网页版的”公众号”进行信息爬取. 这个算是钻了公众号平台的空子. 算是一个巧方法. 但是如果微信封禁了微信个人公众号平台访问其它公众号的”特权”, 这个方法就会失效. 相比于第一种, 这个算是软实力.
产品的完成度来看, wechat-spider 的完成度更高; 数据存储在数据库MySQ中, 便于大规模数据采集与维护; 爬取方式也更具有一般性.
因此准备选择wechat-spider 的技术路线. 但是对它的后台数据库, 我准备使用MongolianDB. 因此, 还需要对这个开源库进行改造. 此外, 我暂时不需要这么丰富的功能, 所以我还需要对其进行剪裁.