爬虫数据持久化方式的选择
系列文章
- 网页爬虫第一课:从案例解构爬虫基本概念
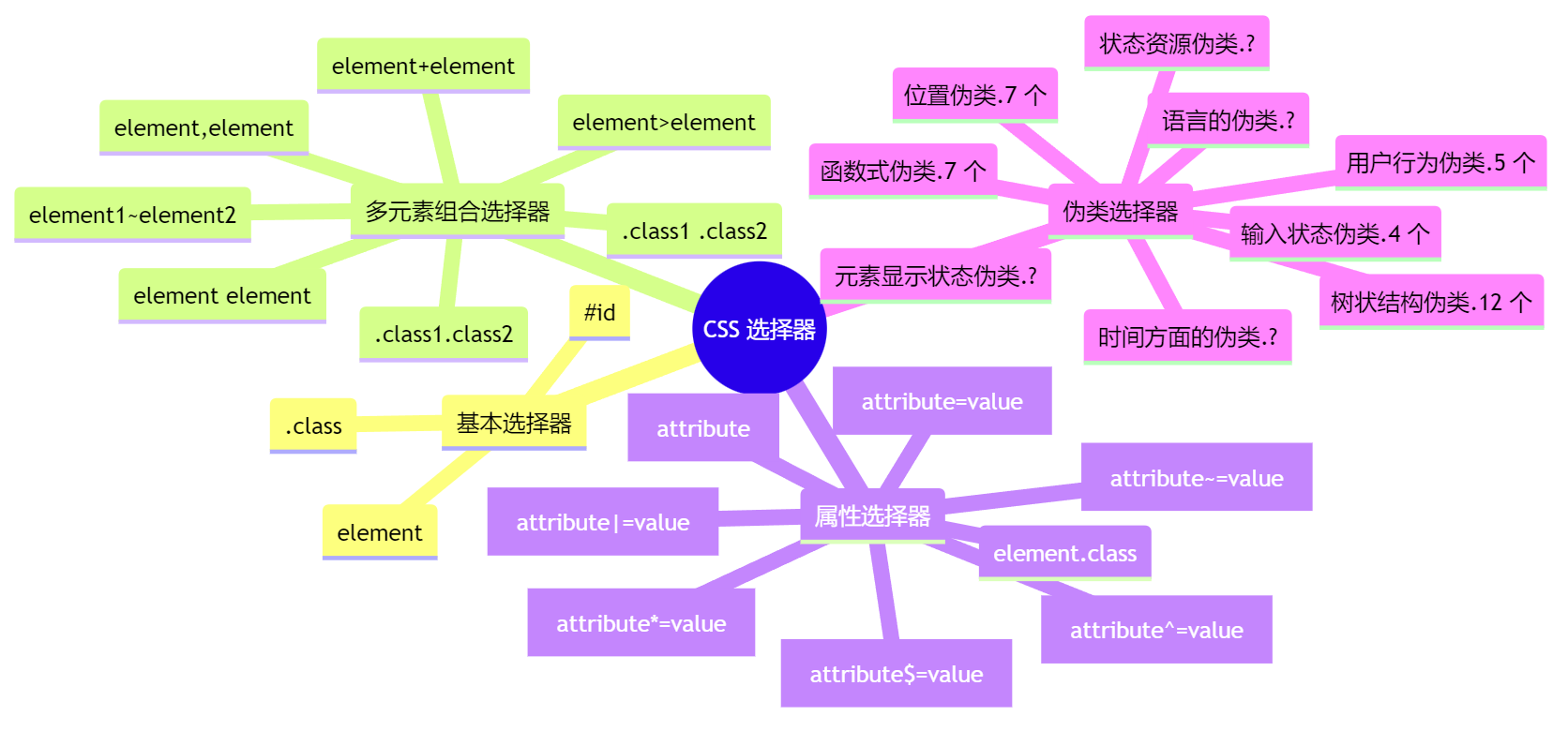
- 填坑18年:我总结的CSS选择器
- 爬虫数据持久化方式的选择
- 爬取静态博客网页以分析本网站拓扑结构
- python程序的性能测试及瓶颈分析
- Python工程项目的规范开发指南
存储方案的选择
爬虫数据的存储目前有以下几种方式:
- TXT文本文件存储
- JSON文件存储
- CSV文件存储
- MySQL存储
- MongoDB文档存储
- Redis缓存存储
- Elasticsearch搜索引擎存储
- RabbitMQ的使用
作为个人使用, 从数据的”存储便捷性-多种工具间的兼容性-可拓展性”的角度出发, 我选择综合使用下述方案:
上面的过程慢慢来. 在本文中今天先学会JSON文件存储.
JSON文件存储
python的json字符串形如:
1 | json_str = [ { |
将python中生成的数据写入到磁盘json文件有两个函数: dumps和dump.
1 | import json |
Or,
1 | import json |
类似地, 从磁盘json文件读取数据到python程序中也有两个函数: loads和load. 在此不再赘述.
MongoDB文档存储
MongoDB是有C++语言编写的非关系型数据库(NoSQL, Not Only SQL). NoSQL是基于键值对的, 而且不需要经过SQL层的解析, 所以速度快, 适合大数据量的存储. MongoDB的数据存储格式是BSON, 也就是二进制的JSON. (前文已经说过, 对于不大的数据量, 我们多以JSON实现数据持久化. 而当数据量大时, JSON可以平滑的过渡到MongoDB).
MongoDB的一些特点使它比较适合爬虫数据的存储. 对于爬虫的数据存储来说, 一条数据可能存在因某些字段提取失败而缺失的情况, 而且数据可能临时调整. 另外, 数据之间还存在嵌套关系. 如果使用关系型数据库存储这些数据, 一是需要提前建表, 二是如果数据存在嵌套关系, 还需要进行序列化操作才可以存储, 这非常不方便. 如果使用非关系型数据库, 就可以避免这些麻烦, 更简单、高效. [1]
我们选择在wsl的Linux环境中操作MongoDB数据库. 这里简要给出MongoDB的安装流程:
Step 1: 安装MongoDB [2]
1 | sudo apt-get install gnupg curl |
Step 2: 启动MongoDB服务 [3]
1 | sudo systemctl start mongod |
命令行操作MongoDB
在mongosh或MongoDB Compass中, 交互式操作. 这里我只给出最小工作流程:
- 了解MongoDB数据库的基本概念: MongoDB Basics
- 连接MongoDB后台服务程序, 并新建(或使用已有的)数据库: 数据库操作
- 在数据库中新建(或使用已有的)集合: 集合操作
- 对于数据库的日常应用, 基本都是围绕CRUD操作进行的: MongoDB CRUD
Python操作MongoDB
这里我仅给出用python将数据写入MongoDB的最小工作流程, 详细的操作可以参考本小节的下述资料.
1 | import mitmproxy.http |
阅读资料:
Extended Offical Tutorial: Python for MongoDB
Store Sensitive Data With Python & MongoDB Client-Side Field Level Encryption
In these situations, you can add an extra layer of security to the most sensitive fields in your database using client-side field level encryption ( CSFLE). CSFLE makes it nearly impossible to obtain sensitive information from the database server either directly through intercepting data from the client, or from reading data directly from disk, even with DBA or root credentials.
MongoDB Change Streams with Python
Change streams allow you to listen to changes that occur in your MongoDB database. On MongoDB 3.6 or above, this functionality allows you to build applications that can immediately respond to real time data changes. In this tutorial, we’ll show you how to use change streams with Python.
Elasticsearch搜索引擎存储
Elasticsearch的优势是可以快速的进行全文搜索, 而且支持分布式搜索. 但是Elasticsearch数据库特别耗费资源,我曾租了一年的云主机作为Elasticsearch服务器——花了不少钱,也没有搞出什么名堂。最难受的是它太重了,每次使用的时候一想到杀鸡用牛刀,瞬间失去了行动的兴趣。
而日常的爬虫应用需求,都是个性化的,所以数据库以轻便为佳。
小结与展望
用MongoDB吧,它轻便,易用;更关键的是,它是非结构化的,对于应付对象元数据不确定的情况比较灵活。
这些特点使MongoDB适合爬虫数据的存储。