自有数据辅助的大语言模型问答精度改进
系列文章

工具选择
这篇文章最初是在一年前我构思的,目的在于通过引用外部数据源,改善LLM回答的精确性,减少“幻觉”。但自己一直没有推动
一年后的今天,我觉得该自用的RAG系统做个了解,才惊觉这个技术已经有了长足的发展:Dify、AnythingLLM、Langflow等已经超脱了LangChain [1] 、LlamaIndex 等基础设施的范畴 [2] ,可以直接为终端用户提供开箱可用的方案。
君子性非异也,善假于物也。作为非专业研究者,我是时候放下执念,从善如流了。通过比较,我最终选择了 RAGFlow . 相比于其它解决方案,RAGFlow对我的吸引力主要来自于如下:
🍔 兼容各类异构数据源
支持件类型丰富文,包括 Word 文档、PPT、excel 表格、txt 文件、图片、PDF、影印件、复印件、结构化数据、网页等。
🛀 全程无忧、自动化的 RAG 工作流
- 全面优化的 RAG 工作流可以支持从个人应用乃至超大型企业的各类生态系统。
- 大语言模型 LLM 以及向量模型均支持配置。
- 基于多路召回、融合重排序。
- 提供易用的 API,可以轻松集成到各类企业系统。
此外,它还能对外提供API接口,以方便我们将RAGFlow的知识外挂能提集成到其它应用。

安装方法
- 🎬 快速开始
- 在PowerShell中打开Windows操作系统的虚拟化功能
Hyper-v(使用 PowerShell 启用 Hyper-V):
Enable-WindowsOptionalFeature -Online -FeatureName Microsoft-Hyper-V -All - 解决端口问题:【已解决】bind: An attempt was made to access a socket in a way forbidden by its access permissions.
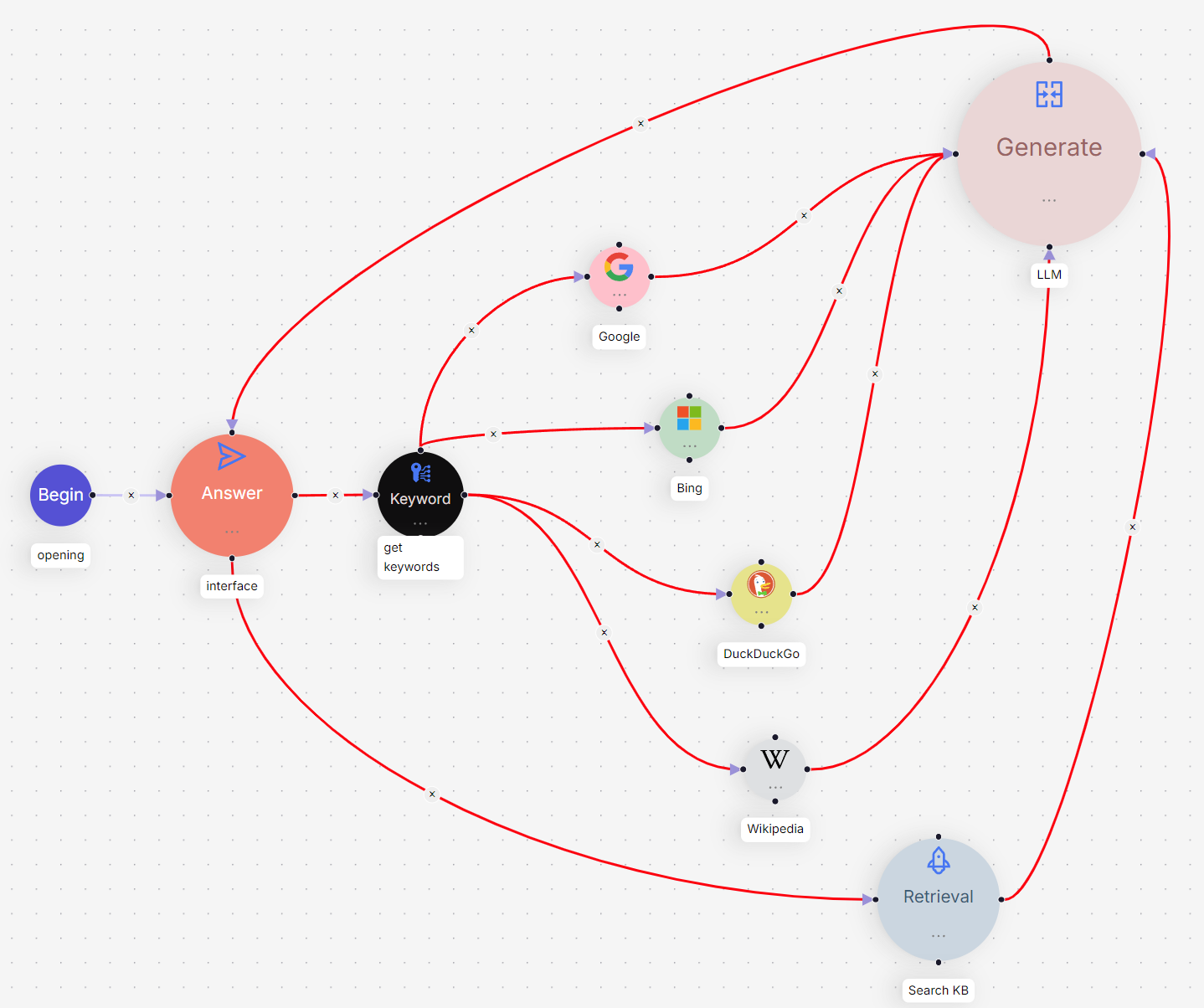
Graph Agent: Search Introduction
在知识库的基础上,我进一步集成了websearch获得的信息。其中,我为输出端定制的提示词可以方便的给出引文,此处备案一下:
1 | Role: You are an intelligent assistant. |
下一步计划
- 提高知识库的Embedding速度
- 优化Graph Agent的工作流,
- 利用Graph Agent的API接口,完善我的Obsidian插件,实现知识库的自动化更新。
参考资料
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 論文範!
相关推荐


评论