大模型在自动驾驶领域的应用(上:可能性)
系列文章
前言
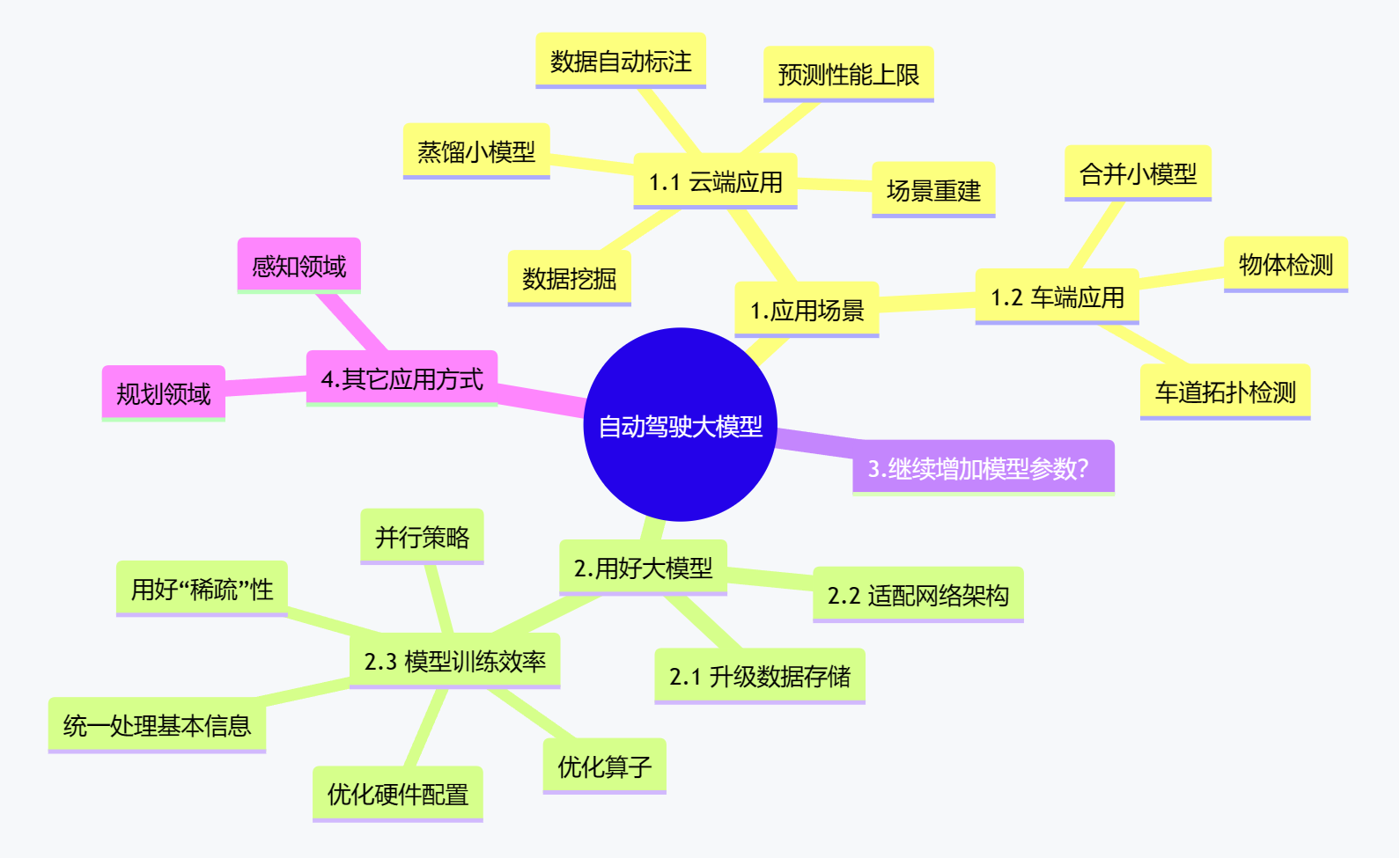
为了探察自动驾驶技术栈在AIGC(生成式人工智能能)热潮下的技术动向,本文对《万字长文说清大模型在自动驾驶领域的应用》进行解构,下面是原文的内容框架:
mindmap
root((自动驾驶大模型))
1.应用场景
1.1 云端应用
数据自动标注
数据挖掘
蒸馏小模型
预测性能上限
场景重建
1.2 车端应用
合并小模型
物体检测
车道拓扑检测
2.用好大模型
2.1 升级数据存储
2.2 适配网络架构
2.3 模型训练效率
优化算子
并行策略
用好“稀疏”性
统一处理基本信息
优化硬件配置
3.继续增加模型参数?
4.其它应用方式
感知领域
规划领域
对于上述内容,我感兴趣的点主要聚焦于以下几个,现简要记录如下。
要点分析
数据挖掘
大模型有较强的泛化性,适合用于挖掘长尾数据;另外,大模型可以较好地从数据中提取特征,然后找到有相似特征的目标。
文远知行的某位专家告诉笔者:假如采用传统的基于标签的方式来挖掘长尾场景,模型一般只能分辨已知的图像类别。2021年,OpenAI发布了CLIP模型(一种文字-图像多模态模型,可以在无监督预训练之后将文本和图像对应,从而基于文本对图片进行分类,而非只能依赖于图片的标签),我们也可以采用这样的文字-图像多模态模型,用文字描述来检索drive log中的图像数据。例如,“拖着货物的工程车辆”、“两个灯泡同时亮着的红绿灯”等长尾场景。
根据上述多模态大模型挖掘长尾场景的方式,我们可以假设下面一种应用场景:假设我们希望从很多图片中找到包含环卫工人的图片,不需要先专门给图片打好标签, 可以用大量包含环卫工人的图片给大模型做预训练,大模型就可以从中提取出一些环卫工人的特征。然后,再从图片中找到和环卫工人的特征比较匹配的样本,从而挖掘出几乎所有包含环卫工人的图片—— 这实际上是一种Zero-shot Learning的方法,可参见《Zero-shot 、One-shot 、Few-shot Learning 简介与应用》、《什么是zero-shot, one-shot和few-shot Learning》。
拓展阅读:
- Paper:Towards Zero-Shot Learning: A Brief Review and an Attention-Based Embedding Network - 2023
- Paper:A Unified Approach for Conventional Zero-Shot, Generalized Zero-Shot, and Few-Shot Learning - 2022
- Paper:Zero-Shot Learning and its Applications from Autonomous Vehicles to COVID-19 Diagnosis: A Review - 2020
- Paper:A Survey of Zero-Shot Learning: Settings, Methods, and Applications - 2019
- Paper:Small Sample Learning in Big Data Era - 2018
- PaperWithCode:Zero-Shot Learning – A Comprehensive Evaluation of the Good, the Bad and the Ugly
- Benchmarks:Zero-Shot Learning
物体检测
一位业内专家告诉笔者:一些真值比较固定的物体适合用大模型来检测。
那么,什么是真值比较固定的物体呢?
所谓真值固定的物体,就是真值不会被天气、时间等因素影响的物体,例如车道线、立柱、灯柱、交通灯,斑马线、地库的停车线、停车位等,这些物体存在与否、位置在哪里都是固定的,不会因为下雨或者天黑等因素改变,只要车辆经过相应的区域,他们的位置都是固定的。这样的物体就适合用大模型来检测。
蒸馏小模型
大模型还可以采用知识蒸馏的方式“教”小模型。何为知识蒸馏呢?用最通俗的话来解释,就是大模型先从数据中学到一些知识,或者说提取到一些信息,然后再用学到的知识“教”小模型。
在实践中,可以先把需要打标签的图片给大模型学习,大模型可以给这些图片打好标签,如此一来,我们就有了标注好的图片,将这些图片拿来训练小模型,就是一种最简单的知识蒸馏方式。
当然了,我们也可以采用更复杂的方式,如先用大模型从海量数据中提取特征,这些提取出来的特征可以用来训练小模型。或者说,我们还可以设计得更复杂,在大模型和小模型之间再加一个中模型,大模型提取的特征先训练中模型,然后再用训练好的中模型提取特征,交给小模型使用。工程师可以按照自己的需求选择设计方式。
从小马智行了解到,基于大模型提取的特征进行蒸馏并finetune,可以得到行人注意力、行人意图识别等小模型,并且,由于在特征提取阶段是共用一个大模型,计算量可以减少。
合并小模型
在车端运用大模型,主要形式是把处理不同子任务的小模型合并,形成一个“大模型”,然后来做联合推理。
:现状 在传统的车端感知模型中,处理不同子任务的模型是独立做推理的。例如车道线检测任务由一个模型负责,红绿灯检测任务由一个模型负责,随着感知任务的增加,工程师会在系统中相应地增加感知特定目标的模型。以前的自动驾驶系统功能较少,感知任务相对容易,但是随着自动驾驶系统功能的升级,感知任务越来越多,假如仍然采用不同任务单独用负责相应任务的小模型来单独推理的方式,系统延迟会太大,存在安全隐患。
:解决方案 觉非科技的BEV多任务感知框架中,是将不同目标的单任务感知小模型进行合并,构成一个能同时输出静态信息——包括车道线、地面箭头、路口的斑马线、停止线等,还有动态信息——包括交通参与者的位置、大小、朝向等。觉非科技的BEV多任务感知算法框架如下图所示:
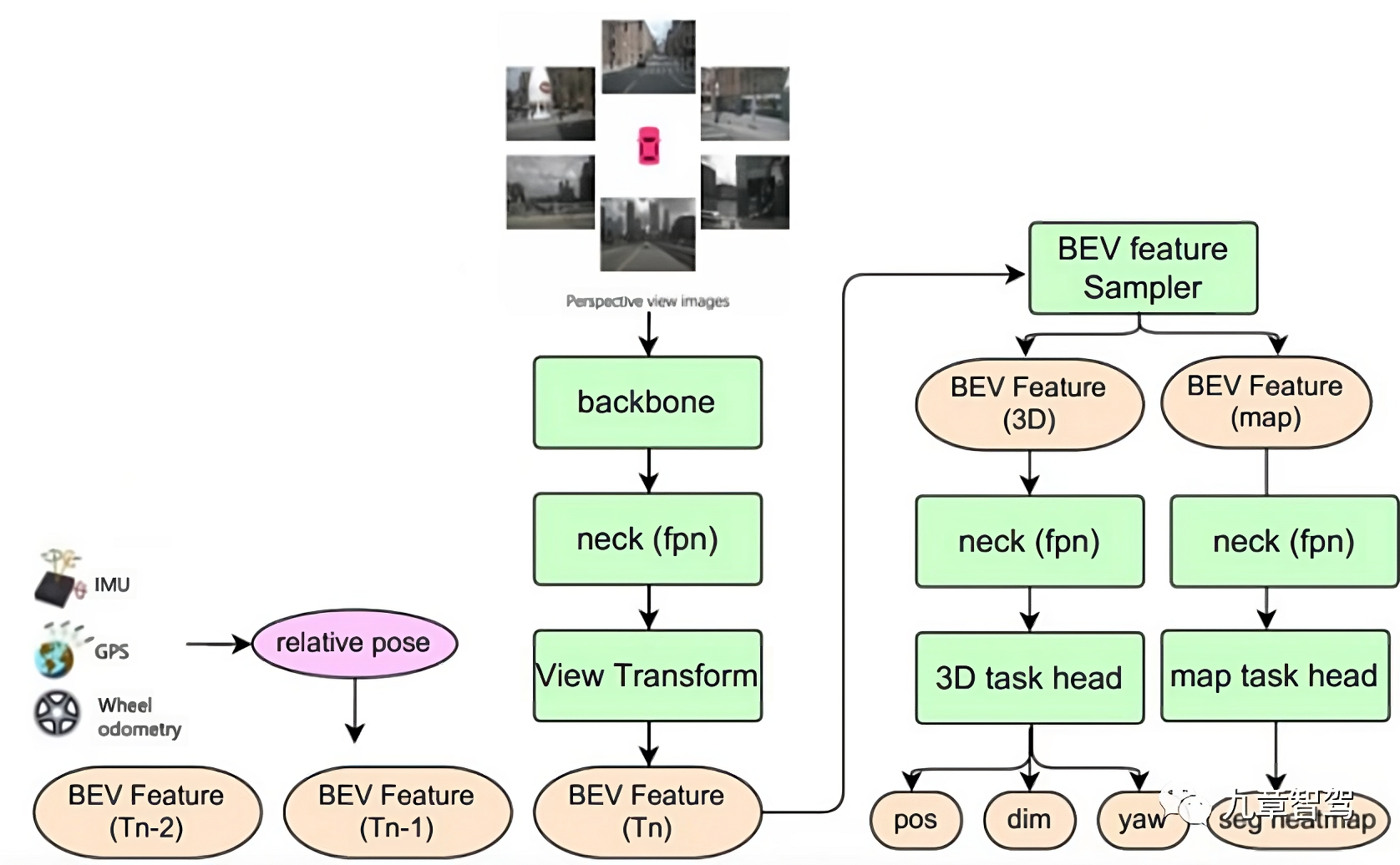
:贡献 该多任务感知模型实现了特征的时序融合——将历史时刻的 BEV 特征存入特征队列,在推理阶段,以当前时刻的自车坐标系为基准,根据自车运动状态对历史时刻的BEV特征做时空对齐 (包括特征旋转、平移),再将对齐后的历史时刻BEV特征与当前时刻的 BEV 特征进行拼接。
:优势 在自动驾驶场景中,时序融合能够提高感知算法的准确性,一定程度上弥补单帧感知的局限。以图中所示 3D 目标检测子任务为例,有了时序融合,感知模型可以检测到一些单帧感知模型无法检测到的目标 (例如当前时刻被遮挡的目标),还可以更加准确地判断目标的运动速度,以及辅助下游任务做目标的轨迹预测。
觉非科技BEV感知技术负责人戚玉涵博士告诉笔者:采用这样的模型架构,在感知任务变得越来越复杂的时候,多任务联合感知的框架能保证感知实时性,也能输出更多、更准确的感知结果提供给自动驾驶系统下游使用。
:缺陷 然而,多任务小模型的合并也会带来一些问题。从算法层面上来说,合并之后模型在不同子任务上的表现可能会有“回退”现象——即模型检测的性能比独立的单任务模型下降。虽然由不同的小模型合并而成的大模型的网络结构仍然可以很精巧,但是合并后的模型需要解决多任务联合训练的问题。
:未来工作 多任务联合训练中,各个子任务可能无法做到同时、同步收敛,且各任务之间会受到“负迁移”的影响,合并后的模型就会在某些特定任务上出现精度的“回退”。算法团队需要尽可能地优化合并的模型结构,调整联合训练的策略,降低“负迁移”现象的影响。
拓展阅读:
- 科普:Simple-BEV:多传感器BEV感知中真正重要的是什么?
- Paper:Simple-BEV: What Really Matters for Multi-Sensor BEV Perception? (ICRA 2023)
- Code:Simple-BEV: What Really Matters for Multi-Sensor BEV Perception?
- Project:Simple-BEV: What Really Matters for Multi-Sensor BEV Perception?
感知领域
CMU Research Scientist Max告诉笔者:用大模型来实现感知任务,核心不是堆叠参数,而是要打造可以‘内循环’的框架。如果整个模型无法实现内循环,或者说没办法实现不断地在线训练,那就很难实现很好的效果。
那么,如何实现模型的“内循环”呢?我们可以参考ChatGPT的训练框架,如下图所示:
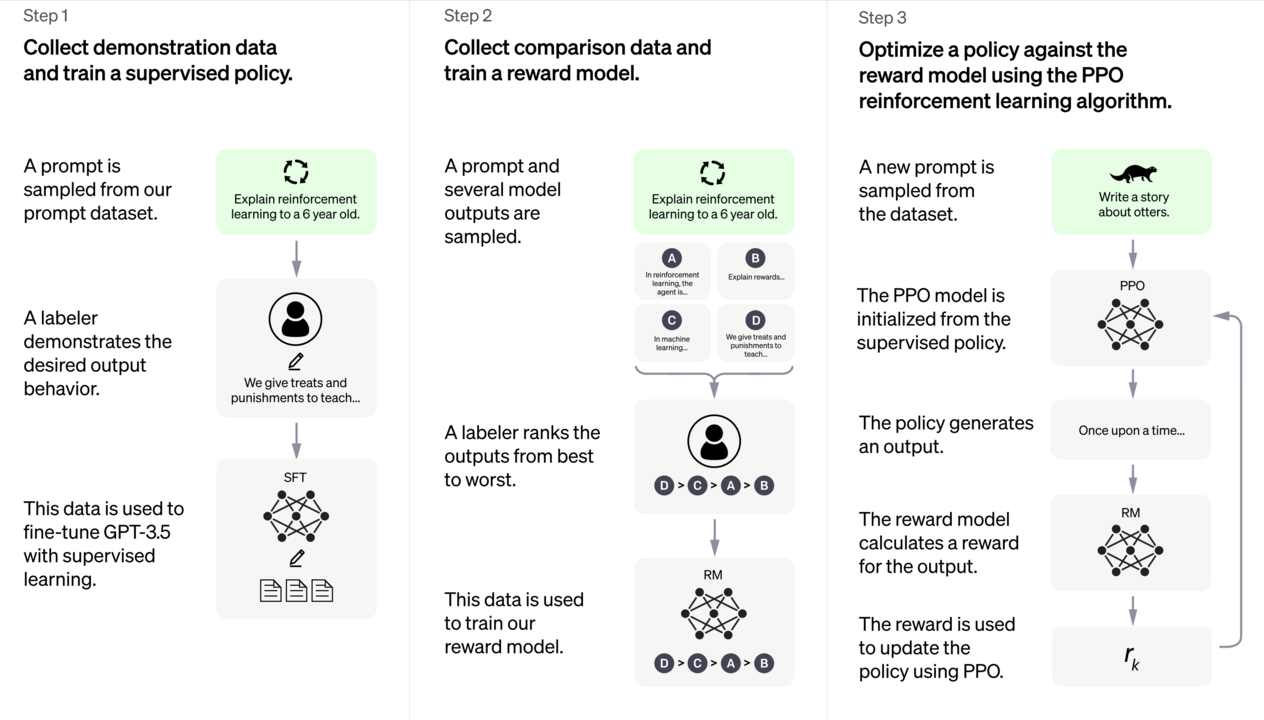
ChatGPT的模型框架,可以分为三个步骤:第一步有监督学习,工程师先采集并标注一部分数据,然后用这部分数据来训练模型;第二步是设计一个奖励模型(Reward Model),模型可以自己输出一些标注结果;到了第三步,我们可以通过一个类似于强化学习的路径,实现自监督学习,用更通俗的语言来讲叫“自己和自己玩儿”,或者说“内循环”。
只要到了第三步,模型就不再需要工程师加入标注好的数据,而是可以在拿到无标注数据后自己计算loss,然后更新参数,如此不断循环,最终完成训练。
“假如在做感知任务的时候,我们可以设计好合适的Reward Policy,让模型训练不再依赖标注数据,就可以说模型实现了‘内循环’,可以根据无标注数据不断地更新参数。”
规划领域?
在围棋等领域,每个步骤的好坏比较容易评判,因为我们的目标一般只包括最终赢得对弈。
然而,在自动驾驶的规划领域,人对自动驾驶系统表现出来的行为的评价体系是不清晰的。在保证安全之外,每个人对舒适度的感受不同,我们可能还希望尽可能快地到达目的地。
换到聊天场景中,机器人每次给的反馈到底是“好”还是“坏”,其实也不像围棋那样有非常清晰的评价体系。自定驾驶也和这一点类似,每个人对于“好”和“坏”有不同的标准,而且他/她可能还有一些很难被清晰地表达出来的需求。
在ChatGPT训练框架的第二步,标注员去给模型输出的结果排序,然后用这个排序结果来训练Reward Model。在一开始,这个Reward Model并不是完美的,但是我们可以通过不断地训练,让这个Reward Model不断地逼近我们想要的效果。
某位来自人工智能企业的专家告诉笔者:在自动驾驶的规划领域,我们可以不断地收集汽车行驶的数据,然后告诉模型什么情况下人会接管(也就是说人会觉得有危险),什么情况下可以正常行驶,那么随着数据量的增加,Reward Model会越来越接近完美。
也就是说,我们可以考虑放弃显式地写出一个完美的Reward Model,而是通过不断给模型反馈的方式来得到一个不断逼近完美的解。对比目前在规划领域通用的做法,即试图依靠人工书写规则显式地找到最优解,先采用一个初始的Reward Model,然后根据数据不断优化的方法,是一个范式的转变。
采用这种方式后,优化规划模块就可以采用一个相对标准的流程,我们需要做的只是不断地收集数据,然后训练Reward Model,不再像传统方法那样依赖于某个工程师对整个规划模块理解的深度。
此外,历史上所有的数据都可以用来训练,我们不用担心某个规则改动之后,虽然解决了当前遇到的一些问题,但是某些之前已经被解决了的问题再次出现,假如采用传统方法,我们可能就会被这种问题困扰。
讨论与总结
为了方便讨论,此处再次给出《万字长文说清大模型在自动驾驶领域的应用》的内容要点:
mindmap
root((自动驾驶大模型))
1.应用场景
1.1 云端应用
数据自动标注
数据挖掘
蒸馏小模型
预测性能上限
场景重建
1.2 车端应用
合并小模型
物体检测
车道拓扑检测
2.用好大模型
2.1 升级数据存储
2.2 适配网络架构
2.3 模型训练效率
优化算子
并行策略
用好“稀疏”性
统一处理基本信息
优化硬件配置
3.继续增加模型参数?
4.其它应用方式
感知领域
规划领域
提炼关键技术
首先,放弃 3.继续增加模型参数?,且不论OpenAI的PI已经认定此路不通,就是这种重型军备竞赛,就不是我这个散仙应该觊觎的。
其次,对于2.用好大模型不是应该在理论研究阶段应该关心的。2.用好大模型 属于神经网络模型的工程部署及其优化——工程的事情只能在工程实践中开展。
然后,对于 “4.其它应用方式” ,提到的感知领域和规划领域是一个很诱人的领域,分别对应着“感知”与“决策”。然而,过于仰望星空;此外,如果没有现实的感知技术基座,也做不起来。
到了最后,我们可以在1.应用场景 选一个“脚踏实地”、又能兼顾“仰望星空”的立足点,涉及以下几个业界关注的点:
“预测性能上限”属于更多的是工程价值。“场景重建”更多是为了给人看的,如果能把这个做好,产品的卖相当然会更好,但不是最迫切的。“数据自动标注”可以算作“蒸馏小模型”的一个步骤,但“蒸馏小模型”却未必一定要“数据自动标注”——如果我们能彻底地解决“蒸馏小模型”的问题,那么“数据自动标注”这个问题自然就不存在了。不去关注“车道拓扑检测”也是类似的原因——“物体检测”已经涵盖了“车道拓扑检测”。
技术发展路径
直接给出技术发展路径的流程图:
flowchart TD
subgraph ide2 ["`**规划领域**`"]
direction TB
强化学习 ~~~ 动态规划 ~~~ 博弈论 ~~~ 其它
end
subgraph ide1 ["`**感知领域**`"]
direction TB
A("(小模型)物体检测") --> B[("合并小模型")]
B --> C("调优(finetune)大模型") --> D("数据挖掘(Few-shot Learning)") & E("(大模型)物体检测")
E --> F(蒸馏小模型) --> A
end
style ide1 fill: #eff8f0, stroke:none
style ide2 stroke:none
落地与展望
关于大模型在智慧交通/自动驾驶领域的落地,我想参考下面拓展阅读的两篇文章,再拓展成一篇新的文章。本文到此为止。
拓展阅读: